My feelings about local large-language models (LLMs) waffle back and forth every few months. New smaller models come out that perform reasonably well, in both speed and output quality, on inexpensive hardware. Then new massive LLMs arrive two months later that blow everything out of the water, but you would need hundreds of thousands of dollars in equipment to run them.
Everything depends on your use case. The tiny Intel N100 mini PC could manage to run a 1B model to act as a simple voice assistant, but that isn’t going to be a useful coding model to put behind Claude Code, Aider, or OpenCode.
Most of what I ask of an LLM is somewhere in the middle. The models that fit on my aging 12-gigabyte gaming GPU were already more than capable of helping me write blog posts two years ago, and even smaller models can do a more than acceptable job today. I don’t need to use DeepSeek’s 671-billion parameter model for blogging, because it is only marginally better than Qwen Next 30B A3B. If you are coding, this is a different story.
I believe I should tell you that I started writing this blog post specifically because I subscribed to Z.ai’s lite coding plan. Yes, that is my referral link. I believe that you get a discount when you use my link, and I receive some small percentage of your first payment in credits.
Z.ai is offering 50% off your first payment, so you can get half price on up to one full year of your subscription. It works out to $3 per month. I aimed for the middle and bought three months for $9. I will talk in more detail about this closer to the end of this blog post!
- Deciding Not To Buy A Radeon Instinct Mi50 With The Help Of Vast.ai!
- How Is Pat Using Machine Learning At The End Of 2025?
Why would you want to run an LLM locally?!
I would say that the most important reason is privacy. Your information might be valuable or confidential. You might not be legally allowed to send your customers’ data to a third party. If that is the case, then spending $250,000 on hardware to run a powerful LLM for your company might be a better value than paying OpenAI for a subscription for twenty employees.
Reliability might be another good reason. I could use a tiny model to interact with Home Assistant, and I don’t want to have trouble turning the heat on or the lights off when my terrible Internet connection decides to go down.
Price could be a good reason, especially if you’re a technical person. You can definitely fit a reasonable quantized version of Qwen 30B A3B on a used $300 32 GB Radeon Instinct Mi50 GPU, and it will run at a good pace. This doesn’t compete directly with Claude Code in quality or performance, but Qwen Coder 30B A3B can be used for the same purposes. Yes, it is like the difference between using a van instead of a Miata when moving to a new apartment, but it is also a $300 total investment vs. paying $17 per month. The local LLM in this case would start to be free before the end of the second year.
Local LLM performance AND available hardware are both bummers!
You certainly have to use a language model that is smart enough to handle the work you are doing. You just can’t get around that, but I believe the next most important factor is performance.
People are excited about the $2,000 Ryzen AI Max+ 395 mini PCs with 128-gigabytes of fast LPDDR5 RAM. There are a lot of Mac Mini models that are reasonably priced with similar or even better specs. They are excited because you can fit a 70B model in there with a ton of context, but a 70B model runs abysmally slow on these DDR5 machines. Prompt-processing speeds as low as 100 tokens per second and token-generation speeds below 10 tokens per second.
While these mini PCs with relatively fast RAM can fit large models, they really only have enough memory bandwidth to run models like Qwen 30B A3B at reasonable speeds. The benchmarks say the Ryzen 395 can reach 600 tokens per second of prompt processing speed and generate tokens at better than 60 tokens per second.
I send 3,000 tokens of context to the LLM when I work on blog posts. Waiting 30 seconds for the chat to start working on a conclusion section for a blog post isn’t too bad, and it will only take it another minute or two to generate that conclusion. I am used to my OpenRouter interactions of this nature being fully completed in ten seconds, but this wouldn’t be the worst thing to wait for.
My OpenCode sessions often send 50,000 tokens of context to the LLM, and it will do this several times on its own after only one prompt from me. I cannot imagine waiting ten minutes, or potentially multiples of ten minutes, to start giving me back useful work on my code or blog post.
Waiting ten minutes for a 70B model would stink, while waiting one minute for Qwen 30B A3B would feel quite acceptable to me.
On the other end of the local-LLM spectrum are dedicated GPUs. You can spend the same $2,000 on an Nvidia 5090 GPU, but that assumes you already have a computer to install it in. The RTX 5090 should run Qwen 30B A3B at a reasonable quantization with prompt-processing speeds at least five times faster than a Ryzen Max+ 395.
I have a friend in our Discord community who is running Qwen 30B A3B on a Radeon Instinct Mi60 with 32 GB of VRAM. These go for around $500 used on eBay, but the older Radeon Instinct Mi50 cards with 32 GB of VRAM used to go for around half that, but the prices have been inching up. There are benchmarks of the Mi50 on Reddit showing Qwen 30B A3B hitting prompt-processing speeds of over 400 tokens per second while generating at 40 tokens per second. That’s not bad for $500!
There just isn’t one good answer. This is all apples, oranges, and bananas here. You can either run big models slowly or mid-size models quickly for $2,000, or you could run mid-size models at a reasonable speed for $500. You would need to figure out which models can meet your needs.
- Deciding Not To Buy A Radeon Instinct Mi50 With The Help Of Vast.ai!
- GMKtec Ryzen AI Max+ 395 mini PC at Amazon
Local LLMs might be fantastic if you can fit within the constraints!
I recently upgraded my computer with a 16 GB Radeon 9070 XT. I upgraded to Bazzite at the same time, and set up Distrobox containers to keep a few things separated. One of those Distrobox containers is a ROCm setup for mucking about with large language models.
I already know that my minimum viable OpenCode model is likely to be Qwen Coder 30B A3B at Q8. That’s around 30 GB of VRAM without context, and OpenCode needs at least 16,000 tokens of context. The only way I am running a model that size would be at a medium pace on a $2,100 Ryzen AI Max 395 mini PC.
I have managed to puzzle out an important nugget of useful information. I can fit Gemma 3 4B at Q6 with its vision model and 4,000 tokens of context in just under 8 gigabytes of VRAM. I can push that up around 16,000 tokens of context if I run the context at Q8 and still fit in around 8 gigabytes of VRAM.
I think this is neat. I have been saying in our Discord community that it would be nice to have Gemma 3 4B running locally, and I’ve been betting that it would fit on a used $100 8 GB Radeon RX580. It’d be a tight fit, but I could drop the max context a little and bring the context quantization down to Q8 if I had to.
A lot of us in the homelab community are likely to have a spare PCIe slot in one of our servers. Spending less than $100 to add an always-on LLM with a decent multimodal model with image recognition capabilities might be awesome. You could ship surveillance camera images to it. You could forward it photos of your receipts. You could tie it into your Home Assistant voice integration.
Having a reasonably capable model that doesn’t fail when your Internet connection drops out might be nice. Sure, it isn’t going to fix your OpenSCAD project’s build script, but it can still do really useful things!
You can try most local models using OpenRouter.ai
I am a huge fan of OpenRouter. I put $10 into my account last year, and I still have $9 in credits remaining. I have been messing around with all sorts of models from Gemma 2B to DeepSeek 671B and everything in between. Every time I have the urge to investigate buying a GPU to install in my homelab, I head straight over to OpenRouter to see if the models I want to run could actually solve the problems that I am hoping to solve!
I used OpenRouter this week to learn that Qwen 30B A3B is indeed a viable LLM for coding with things like Aider, OpenCoder, and the Claude Code client. That gives me some confidence that it could actually be worthwhile to invest some of my time and money into getting a Radeon Mi60 up and running.
The only trouble is that the Qwen 30B that I tested in the cloud isn’t as heavily quantized. I would need to run Qwen 30B at Q4_K_M, and the results will be degraded at that level of quantization. That may be enough to push the model beyond the point where it is even usable.
Testing the small models at OpenRouter helps you zero in on how much hardware you would need to get the job done, but it most definitely isn’t a perfect test!
Tools like OpenCoder rip through tokens!
Listen. I am not a software developer. I can write code. I occasionally program my way out of problems. I write little tools to make my life easier. I do not write code eight hours a day, and I certainly don’t write code every single day.
I have found a few excuses to try the open-source alternatives to Claude Code, like Aider and OpenCode. They eat tokens SO FAST.
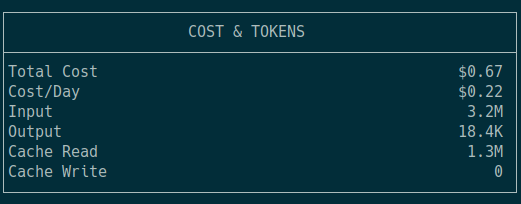
Don’t trust the cost! Some of those 3.2 million tokens over the two-day period were using various paid models on OpenRouter, while more than half were free via my Z.ai coding plan
It took me 11 months to burn through 80 cents of my $10 in OpenRouter credits. Chatting interactively to help me spice up my blog posts only uses fractions of a penny. One session with OpenCode consumed 18 cents in OpenRouter credits, and I only asked it to make one change to six files. I repeated that with two other models, and I used up as much money in tokens in an hour as I did in the previous 11 months.
Blogging with OpenCode
This week is the first time I have had any success using one of the LLM coding tools with blog posts. I tried a few months ago with Aider, and I had limited success. It didn’t do a good job checking grammar or spelling, it didn’t do a good job rewording things, and it did an even worse job applying the changes for me.
OpenCode paired with both big and small LLMs has been doing a fantastic job. It can find grammar errors and apply the fixes for me. I can ask OpenCode to write paragraphs. I can ask it to rephrase things.
I don’t feel like my blog is turning into AI slop. I don’t use sizable sections of words that the robots feed to me. I ask it to check my work. I sometimes ask it to rewrite entire sections, or sometimes the entire post, and I sometimes find some interesting phrasing in the robot’s work that I will integrate into my own.
I almost always ask the LLM to write my conclusion sections for me. I never used their entire conclusion, but I do use it as a springboard to get me going. The artificial mind in there often says cheerleading-things about what I have worked on. These are statements I would never write on my own, but I usually leave at least one of them in my final conclusion. It feels less self-aggrandizing when I didn’t actually write the words myself.
Trying out Z.ai’s coding plan subscription
A handful of things came together around the same day to encourage me to write this blog post. I decided to try OpenCode, it worked well on my OpenSCAD mouse project and my blog, and I learned about Z.ai’s $3-per-month discount. I figured out that it would be easy to spend $1 per week in OpenRouter credits when using OpenCode, and I also assumed that I could plumb my Z.ai account into other places where I was already using OpenRouter.
Z.ai’s Lite plan using GLM-4.6 is not fast—I was using OpenCode with Cerebras’s 1,000-token-per-second implementation of GLM-4.6 via OpenRouter. I was only seeing 200 to 400 tokens per second, which is way better than the 20 to 30 tokens per second that I am seeing on my Z.ai subscription. They do say that the Coding Pro plan is 60% faster, but I have not tested this.
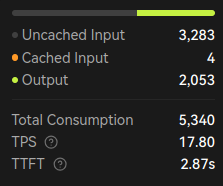
These are the stats from one interaction with GLM-4.6 on my Z.ai subscription using LobeChat
I wound up plumbing my Z.ai subscription in to my local LobeChat instance and Emacs. The latency here is noticeably slower than when I connect to large models on OpenRouter. My gptel interface in Emacs takes more than a dozen seconds to replace a paragraph, whereas DeepSeek V3.2 appears to respond almost instantly.
It isn’t awful, but it isn’t amazing. I would be excited if I could use just one LLM subscription for all my needs, but my LobeChat and Emacs prompts each burn an infinitesimally small fraction of a penny. I won’t be upset if I have to keep a few dollars in my OpenRouter account!
I was concerned that I might be violating the conditions of my subscription when connecting LobeChat and Emacs to my account. Some of the verbiage in the documentation made me think this wouldn’t be OK, but Z.ai has documentation for connecting to other tools.
OpenCode performance is way more complicated. I am not noticing a difference in my limited testing. This may be due to GLM-4.6 being a better coding agent, so I might be using fewer tokens and fewer round trips for OpenCode to get to my answers. I’ve since written a detailed comparison of Devstral 2 with Vibe CLI vs. OpenCode with GLM-4.6 that looks at how these tools feel in practice for casual programmers.
I have only been using my Z.ai subscription for two days. I expect to write a more thorough post with my thoughts after I have had enough time to mess around with things.
Conclusion
Where does all this leave us? After spending so much time digging into both local LLM setups and cloud services, I firmly believe that there isn’t one right answer for everyone.
For my own use case, I might eventually land on a hybrid setup with both a local setup in my homelab and a cloud subscription for the heavy lifting. For now, I’ll keep using OpenRouter for short, fast prompts and testing new models. The inexpensive Z.ai subscription, while a little slower, will do a fantastic job of keeping me from accidentally spending $50 on tokens for OpenCode in a week—that $6 per month ceiling will be nice to have!
The most important thing I learned is that you should test before you buy. OpenRouter has saved me from making at least two expensive hardware purchases by letting me try models first. For anyone else trying to figure out their own LLM setup, I’d recommend the same approach.
If you’re working through these same decisions about hardware, models, or services, I’d love to hear what you’re finding. Come join our Discord community where we’re all sharing what works (and what doesn’t) with our different LLM setups. There are people there running everything from tiny local models, to on-site rigs costing a couple thousand dollars, to running everything in the cloud, and it’s been incredibly helpful to see what others are actually using in the real world.
The LLM landscape changes so fast that what’s true today might be outdated in three months. Having a community to bounce ideas off of makes it much easier to navigate without wasting money on hardware that won’t meet your needs.